
When chilling out, or playing games, I love to listening to trance and EDM. When I was younger, I’d make playlists based on my growing MP3 collection. But now days I just stream on YouTube or Spotify. Today we’ll be talking about something different, namely why and how I figured out how to read very large XML files.
Although my favourite genres have grown over the years, Spotify (and most others) fail to really get trance or EDM. They just sort of just classify music in distorted idealistic way. With mood boards, playlists from strangers, awkward artist created accounts to promote similar music etc… To me it’s all a bit daft, you can’t just pick a genre, or a record label and go from there.
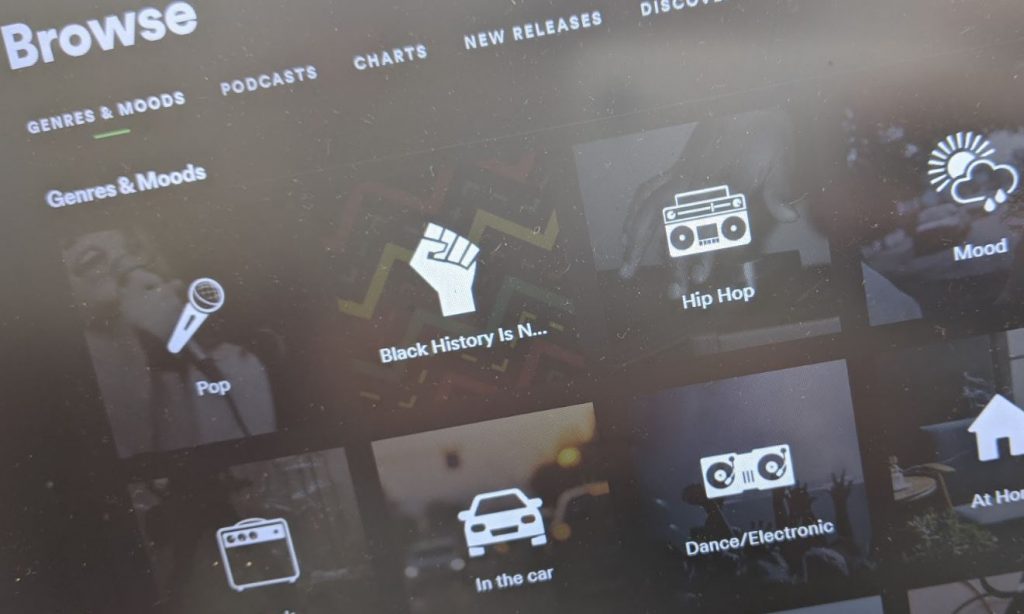
Which brings me to a side project I started working on last week called Label Tracker. The idea? Make a simple, no frills search engine website that puts record labels and genres first. Give people the ability to play the music they find on their favourite platform (Spotify, YouTube Music etc..). And enable them to even create playlists to follow etc…
Apparently, I need a lot of XML data!
You can probably guess that in order for me to create a record label search engine, I need to get the data from somewhere. Research led me to discover that Discogs (a famous online music archive) offers free API and XML data dumps! These data contain almost every release/artist/label ever recorded, so it’s perfect for what I need. The only problem is that the dumps are actually multi-gigabyte XML files, with one of them being over 50GB (uncompressed)!!!!
I realised quickly that I needed to find a reasonable way to import the data into a database. So I began writing a .NET Core application to do so. Issue is how do I read files this big? Normally I’d use a deserialization utility like XDocument. This won’t work for the big XML files though as XDocument loads the entire document into memory first, which is not viable when the best computer I have has 32GB of ram. The files also come as GZip archives, which adds another level of time consumption to the process.
The original plan
- Stream data straight from the GZip archive, decompressing as I go.
- Maintain a collection buffer so that I can parse the XML manually with my own basic tokenizer.
- When processing found records, parse, clean-up, and add to a pool ready to be imported.
- Asynchronously insert records onto the database when the import pool is not empty.
Bottlenecks
My first attempt showed that the reading system was as fast as I wanted. But I quickly discovered that a number of bottlenecks were tanking performance:
- Although I used my database connection efficiently, the insert commands were very slow.
- The larger the buffer I set, the longer it seemed to take.
- I also had a major problem with duplicates. For example; to make sure I don’t add two artists with the same name, I have to maintain a collection of artist names in memory.
Improvements
To combat the bottlenecks I found, I made the following changes:
- I separated the reading and importer parts of the application into 2 separate worker threads. Allowing them to work independently frees the reader to process data faster.
- It seems C# gets very inefficient when a String is longer than a specific size. So I have limited the buffer to a range of 40-100kb. Testing reveals that this was the most optimal for my purposes.
- A refactoring of the import pool took place to make it thread safe. This involved using the Concurrent utilities under the System.Collections namespace in .NET Core. This allows the reader to pass primitives to the importer without the app crashing.
- Inserting one record at a time into a database is slow. So I created a query builder to generate insert statements with up to 50 inserts at a time. This made a drastic speed increase!
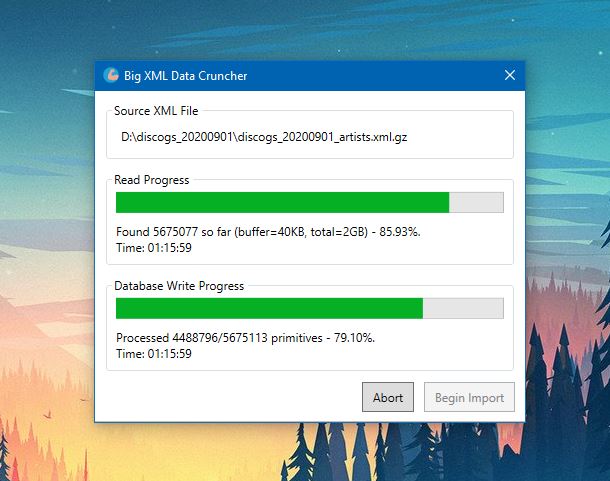
I’ve tested all of the XML data dumps that I need to regularly process. It is now running fast enough that I can process the whole lot on my laptop within about 8hrs. Much faster than the 40+ hours I predicted before the optimisations. I need to test further, but I suspect running on my AMD Threadripper system should yield even faster results.
Integrating Into Spotify
Surprisingly one potential stumbling block has appeared for the project. Spotify offers an API that allows you to do a lot for users, so naturally I want to integrate it into the project. They stipulate however that commercial apps that could potentially make money need to apply for approval before going live. And to be honest, if the project is at-all successful, I would like to make at-least something from it.
So on Sunday last week I sent an application to Spotify via their approval form explaining what the plans for the project are, including what monetization I’d make if any (most likely AdSense). However I have not yet had a response, though I suspect this duration is normal.
If the application is denied, it’s not the end of the world. I’ve looked at other possibilities, and it looks like integrating into either YouTube Music, or iTunes are very viable alternatives too. At the end of the day, I am free to use the Discogs data because it has a CC0 No Rights Reserved license. So I don’t need Spotify’s permission to the project viable, or even to make it a success. But it would be nice if they approved all the same!
The Website
Whilst dealing with the API and data side, I also spent some time building the website prototype. For projects like this I like to use a framework I’ve been working on over the last few years called Panini PHP. Basically it’s a highly cut-down analogue of other systems like Laravel. It still uses Symphony, and Composer, but has a more friendly routing and database system. And it beats the snot out of Laravel when it comes to speed 🙂
Here is a screenshot of how the site looks at the moment running on my localhost WAMP. When it’s ready for public testing, I’ll make a post on the blog here so you can try it out! Lets cross our fingers that Spotify gives me the thumbs up this week, so that you’ll also be able to try some of the cool features I’ve added!
Wrapping Up
This post has been a bit of a switch up from the usual game engine development stuff I talk about. My main project is still Xentu, And will be for the foreseeable future. However I do work on other stuff, and feel it could be interesting for readers to see what else I get up to.
I have a post coming up talking about a handheld games console I am building to showcase the game engine, and another talking about adding sound capabilities to Xentu! So stay tuned, and there will be plenty of new content over the next few weeks.
Thanks again for visiting, have a great week!
Koda